Shin'ichi Satoh's Lab
Welcome to Shin'ichi Satoh's Lab homepage at NII!
Research in our lab focuses on multimedia understanding and knowledge discovery. Especially, we aim to create an intelligent computer system which can see and understand the visual world.
We accept graduate students from Department of Information and Communication Engineering, Graduate School of Information Science and Technology, the University of Tokyo. Our lab is in National Institute of Informatics, Japan.
News
- [2024.7.16] One paper was accepted by ACM Multimedia 2024!
- [2024.7.1] Two papers were accepted by ECCV 2024!
- [2024.6.17] One paper was accepted by IJCV!
- [2024.6.1] One paper was accepted by CBMI 2024!
- [2024.4.22] One paper was accepted by SIGGRAPH 2024!
- [2023.12.9] One paper was accepted by AAAI 2024!
- [2023.10.23] One paper was accepted by IEEE TMM!
- [2023.10.7] One paper was accepted by EMNLP 2023 Main!
- [2023.9.21] One paper was accepted by NeurIPS 2023!
- [2023.7.25] One paper was accepted by ACM Multimedia 2023!
- [2023.7.13] One paper was accepted by ICCV 2023!
Research projects

Large-scale fast object detection
We extended R-CNN to larger scale, which enables immediate and accurate object category detection from a large image databas. R. Hinami and S. Satoh, "Large-scale R-CNN with Classifier Adaptive Quantization", ECCV 2016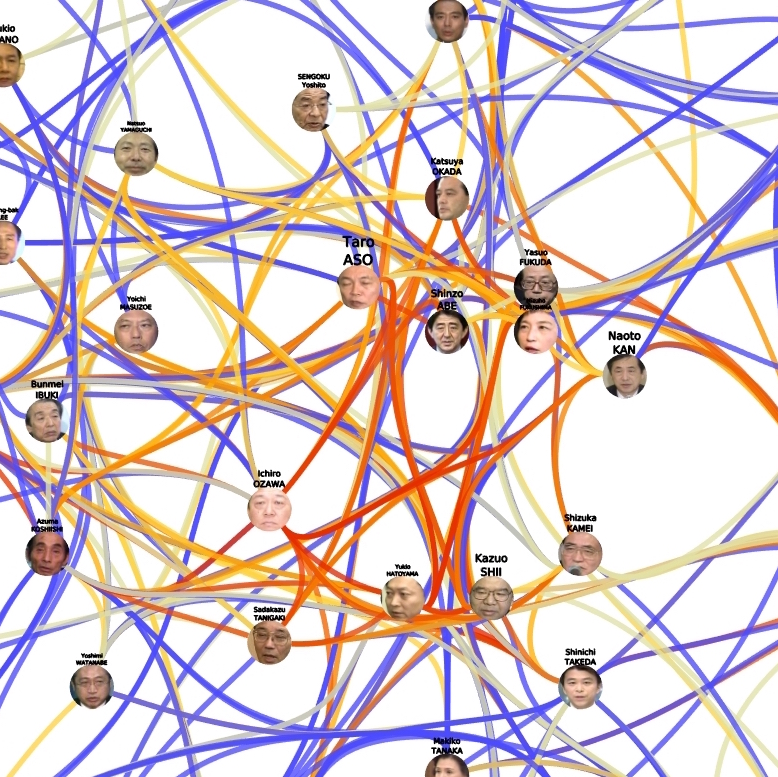
Multimedia Analytics
Explore, analyze, and visualize archives of multimedia content by bringing together data science and computer vision for the support of real world applications such as social sciences, media studies, and even marketing.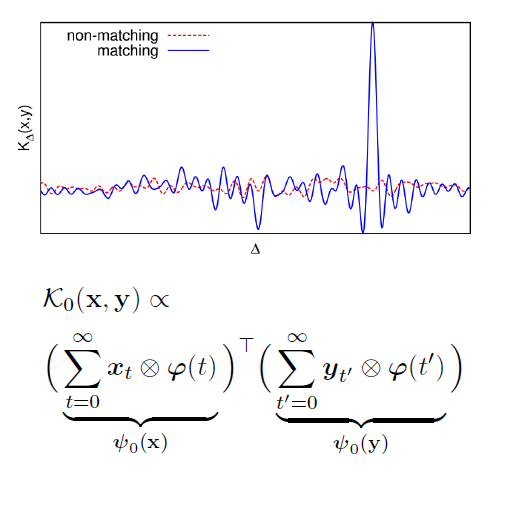
Temporal Matching Kernel with Explicit Feature Maps for Video Event Retrieval
We propose a new video representation for video event retrieval. Given a video query, the method is able to efficiently retrieve similar video events or near-duplicates along with a precise temporal alignment. ``Temporal matching kernel with explicit feature maps,'' ACM Multimedia 2015.